The Idea
I had a brilliant idea yesterday, and couldn’t wait to get home so I could start coding it. Things were moving along great. I had my database created, I’d gotten Code Igniter configured and running with my standard set of libraries, helpers, etc. and I was hammering away at some code.
Damnation
And then it happened. I got to the heart and soul of the application: the part that interacted with the NewsGator API. Almost instantly, my entire world crashed in around me.
What’s that? You’ve never dealt with the NewsGator API? Consider yourself lucky. Only murderers and rapists should be doomed to such a fate. The NewsGator API is by far, and without a doubt, the worst API I have ever dealt with - and I’ve dealt with quite a few in the past.
The Spectrum
Think of the overall web API spectrum as a scale.
On the one end, you’ve got Yahoo!. Yahoo! offers what could be considered the Utopia of web APIs. They do your “standard” XML and SOAP interfaces, but they also offer a plethora of other options for many of their services: various REST APIs, JSON, and even plain old serialized PHP are all readily available for use. Whatever the language, whatever the platform, you can get data out of Yahoo! with a minimum of pain.
On the far, extreme, totally opposite end of this vast, gigantic, absolutely humongous spectrum of available APIs is NewsGator. You name it, they’ve probably done it wrong with their API. First problem? SOAP.
Ok, SOAP sounds great, and I have no doubt that it has its purposes, but for the love of god people… why? There are so many other alternatives available that could greatly simplify the process we really care about here: getting bits back and forth. I won’t say I have to end-all of answers as to the “perfect” format, but I can readily recommend any number of alternatives to SOAP.
REST? When? I’m working around bugs 24x7!
What? NewsGator has a REST API?
Well, you’d be partially right, at least. You POST your request and get back the same gobbly-gook XML data that you’d have gotten from the SOAP interface. This seems a bit backwards to me, since SOAP is XML-based and a SOAP interpreter would therefore also interpret the XML you’re receiving back (well, most of it). Tacking an XML parser on top of your REST API just seems perverted.
Oh yeah, there’s also no documentation for the REST API… None… Notta. The only thing you’ll find of help is a poorly-formatted PDF document that seems to kinda, maybe, sorta, give you a general idea of what’s going on… To top it off, apparently there’s no equivalent REST-based API for the SOAP-based interface called “PostItem”, according to forum posts.
Sample, Shmample!
Finally, the only code samples you’ll get from NewsGator are in .NET (C# to be precise). Talk about a long way migrating that over to PHP or, god save you, something like Ruby… Yahoo!, on the other hand, provides examples for most of their APIs in .NET, Java, Perl, PHP (4 and 5), Python, etc…
The Adventure Begins…
In my journeys over the past two days, I’ve hit more bumps in the road than I do on my way to work… In the mountains… In the middle of the ghetto… Through a huge swamp… Infested with mutant turtle speed bumps. It’s like a huge real-life version of Frogger, all wrapped in disgusting XML nastiness.
First, and not the least of my problems, has been a bug in PHP’s SOAP implementation that apparently has existed since September of 2004 and which was supposedly fixed in CVS in March of 2005. Here it is July of 2007, and I’m still hitting a problem parsing out a WSDL file that contains a ref attribute in it.
Alright, I know, we’re here to talk about NewsGator’s crappy API, not PHP’s crappy SOAP implementation1.
NameThatTune
As for NewsGator, let’s start small, shall we?
Ever noticed a difference in naming styles between .NET developers and those developers more commonly found on *nix platforms (Perl, Python, etc.)? Of course I have no empirical data to back me up here, but it seems like .NET developers commonly use functions that FollowACamelCasedNamingPattern, while *nix developers_prefer_to_space_things_out_with_underscores.
I’m sure it’s just personal preference, but I prefer the underscored version, which just seems more easily read to me. That said, NewsGator has a serious case of .NET-itis2.
Now it’s time for some real complaints. Let’s dive in.
You’re Lucky Number 17!
One of the first things you’ll obviously want to do when dealing with RSS feeds is get a list of the user’s subscriptions, right? For that you’d probably want the GetSubscriptionsList call… Or, as it’s called in the WSDL declaration, just GetSubscriptions (remember that…). What does the documentation say this call returns?
The result of this call is an OPML document with NewsGator extensions.
Yes, the only link about these extensions points to the raw XSD definition. No further documentation on what exactly each of the returned fields means is forthcoming. To top it off, we’ve taken SOAP and XML to another level entirely. Stick that OPML in your PHP pipe and try to smoke it, fool… You’ll end up using the built in XML parser and looping through looking for tags of the type OUTLINE, if that’s any hint.
So what does the call actually spit back? Well, it’s a huge list of feeds (which I parsed out into an array). Each feed has a number of detail items (16, in fact - and remember, none of them are documented). Some of these items are self-explanatory, such as “TITLE”, “NG:ID”, and “XMLURL”. Others aren’t quite so helpful: “DESCRIPTION” (My blog’s tagline, for instance, is stored in “TEXT”), “NG:SYNCXMLURL”, “NG:UNSEEN”, and “NG:USEDEFAULTCREDENTIALS” among them.
Alright, great. Now I’ve got a list of subscriptions for the user. How many unread items are in each? Well, out of those 16 fields I just got back for each feed in GetSubscriptions, one of them is “NG:UNREAD”. It’s a boolean value.
Apparently we’re meant to use the call GetSubscriptionCounts for this purpose. It returns a similar OPML document as its previous counterpart, but only contains 9 fields for each post this time. Out of those 9 fields, 8 of them are exactly identical to those found in GetSubscriptions. The 9th? “NG:UNREADCOUNT”. And why couldn’t we just make it the 17th field for GetSubscriptions and used a single call? Better yet, how about eliminating “NG:UNREAD” and simply using “NG:UNREADCOUNT” for the same purpose? Guess what, if it’s 0, there aren’t any unread items!
Now the fun really starts!
Spin the Wheel and Place Your Bets! Your Parameter could be the lucky winner!
They say a picture’s worth a thousand words, so we’ll let them do some of the talking here.
Remember our good friend GetSubscriptions? Take a look at its parameters, as per the online documentation:
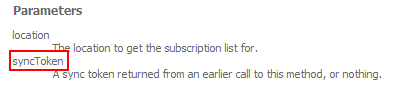
Now that we’ve got a list of subscriptions, let’s pull in all the items for each feed. For that, we’d use GetNews. Check out its documented parameters:
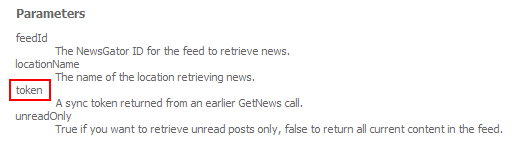
Wait, what? Is it “token”, or “syncToken”? Make up your minds! With all this SOAP-based nonsense, I’m copy-and-paste’ing my brains out, and suddenly you throw a wrench into the clockwork!
Far from a unique incident, however, we can’t let GetSubscriptions and GetNews take all the blame… GetNews appears to be a bad influence, since it doesn’t play well with other calls either. Another GetNews highlight:
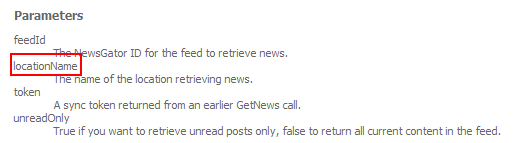
As you can see, our redundant friend GetSubscriptionCounts doesn’t quite match either:

Think you’ve seen enough now? Well, we’re not quite done yet… Just in case format blunders, missing documentation, and parameter SNAFUs weren’t your style, how about “undocumented features”3?
Presto! Watch Me Pull a Parameter out of My Hat!
Not to leave well enough alone, let’s make one more last jab at good old GetNews. I realized my parameter naming problem and corrected it, only to be met with a remarkably similar error telling me that I had an invalid value for the “stripMarkup” parameter, that it couldn’t be left blank.
The stripMarkup parameter? Am I the only one who missed that? Did you see that in any of the screenshots I just posted of GetNews parameters? Let’s look again at the extent of the documentation for this API call:
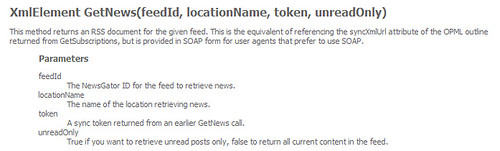
No, apparently it’s not just me. If you click on through to the SOAP Endpoint, NewsGator provides a helpful test mechanism for each of their API calls. Along with SOAP 1.1, 1.2 and REST mockup requests, they provide a simple HTML form that does an HTTP POST to the REST API and spits back the raw XML you’d get as a response.
Loading up this test form, I see where my error comes from:
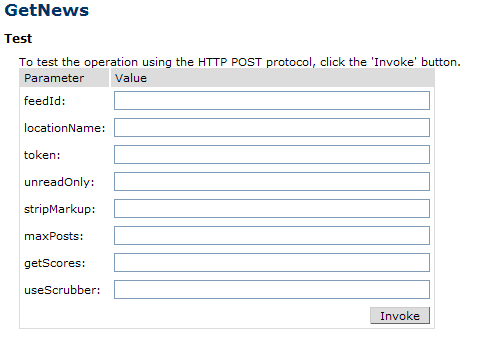
Wait a minute! Where did all those extra fields come from? Those aren’t mentioned anywhere else! The only way you could find those is by looking at the raw XML of the WSDL file4. Whereas at least some of the other non-mentioned parameters we’ve seen have been slightly user-intuitive, some of these are absolutely meaningless to me. What the hell is the difference between “stripMarkup” and “useScrubber” anyway?
Try… Catch… Finally…
So that’s it. Everything I hate about the NewsGator API, all condensed down into one single (albeit lengthy) rant. It’s all laid out there on the line for anyone to see. Do what you will with it. With any luck, NewsGator will track down my post and (hopefully) fix some of these problems. Even if you just want to use these points as examples of what not to do when building your own web API, at least some good will have come from it all.
And to be perfectly clear, I want to make sure no one walks away from this thinking the API is a total loss. To be fair, there are a lot of good points about it. I think their sync token concept has some really strong points (even if it is confusing at first), and really strengthens their process of syncing so much data back and forth without totally bogging down everyone’s bandwidth in between.
I also don’t want to be thought of as making a personal attack here. As I recall, Gordon at NewsGator was their head API guy a while back, and he was always willing to jump in and help. The first few times I had trouble with the API, oh so long ago, he found my blog and did everything he could to help me through my problems, even though he knew nothing about PHP. He was a great guy, and for all we know this entire API was inherited in some bastardized form from a previous developer.
I also got a comment from Greg Reinacker on one of my other blog posts on the subject, and he too was very eager to help. It’s clear people aren’t the problem here (well, at least on the intentions and motivational sides of the equation), because NewsGator obviously has some amazing talent and passion working for them.
The one thing I can’t figure out through all of this, though, is how the hell NewsGator has managed to build so many products on top of this API. I’m one person and I can’t figure this out - how have they managed to coordinate an entire team of developers, geographically dispersed, and get them all on the same page with this, across so many different programming languages (.NET to Cocoa to Java) and platforms (Windows to OS X to Mobile)? It boggles the mind…
- For the record, I also attempted to use NuSOAP, as I’ve tried in the past. Even after renaming all the “SoapClient” class declarations to “NuSoapClient” to avoid conflicts with the PHP5 native implementation, there are several hurdles to overcome. Eventually, I gave up and went with the PHP-native version, expecting it to have better support than NuSOAP, which appears to have been abandoned for several years. ↩
- Which really makes sense, considering it’s coded in ASP… ↩
- The “politically correct” phrase for a “bug” these days… ↩
- Which I suspect is used to auto-generate these forms, as a matter of fact. ↩